Advanced GAN for Multispectral Image Classification and Generation
A neural network that classifies and generates multispectral images from 1 to any channels with precision
Description
Conditional StyleGAN2 is a Generative Adversarial Network that classifies and generates multispectral images from 1 to 5 channels with precision using a modified StyleGAN2 architecture. This project was developed as a bachelor's thesis at University of Santiago de Compostela.
The network is composed of two subnetworks: a discriminator and a generator. The discriminator has an architecture similar to a convolutional network. The initial blocks perform convolutional operations to reduce the information contained in the images into a latent vector of smaller dimensions, and the final block consists of a dense layer with as many output neurons as there are classes to classify.
The generator starts from an initial noise tensor. Through its blocks, the generator progressively constructs the image by performing inverse convolutional operations that increase the resolution of the tensor until it reaches the same dimensions as the images in the training set.
To know more details of the netowork read StyleGAN2 paper or my thesis.
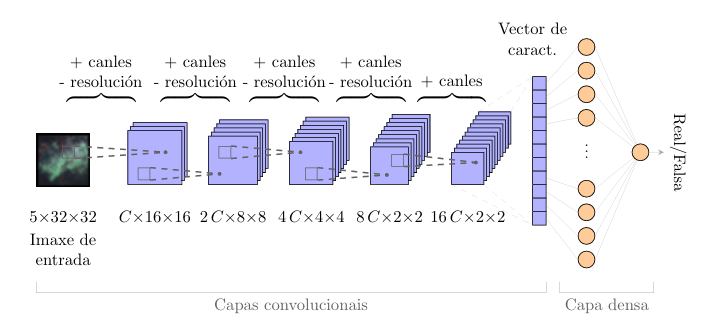
Discriminator schema
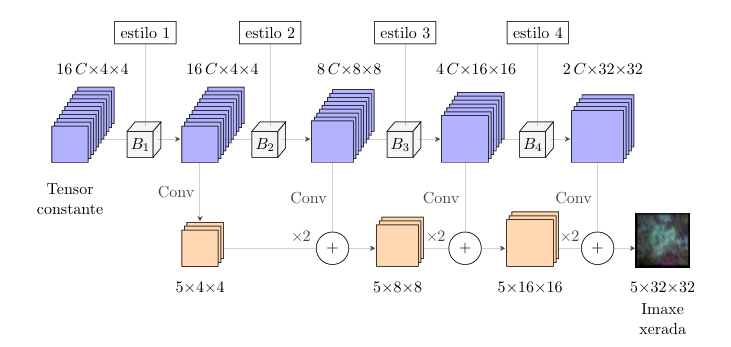
Generator schema
Features
Multispectral Classification
The network classifies multispectral images using a modified StyleGAN2 architecture. To classify multispectral images, it is necessary to preprocess them with a segmentation algorithm and calculate the centres of the segmented regions to extract patches from each multispectral image.
RGB Classification
The network is also capable of classifying RGB and black-and-white images. In these cases, preprocessing with a segmentation algorithm is not required, as the network can classify the images directly.
Image Generation
At the end of the training and during the training process, the network is capable of generating images of the same size as the training images. The generated images are similar to the training images, but they are not identical.
Adaptative Learning Rate
One of the modifications made to the StyleGAN2 architecture is the inclusion of an adaptive learning rate. This modification improves the network's convergence during training with respect to the classification task.
Results
A brief summary of the results obtained with the network is presented here. The network was trained on a simple dataset, like MNIST, as well as a more complex dataset of multispectral images. The results of the network are shown for both classification and generation tasks.
Classification results with MNIST
Some initial experiments were conducted using the MNIST dataset. A training set with 59,000 examples and a validation set with 1,000 examples were used. The classification results were similar to those obtained by other networks, with an overall accuracy of 95.52%.
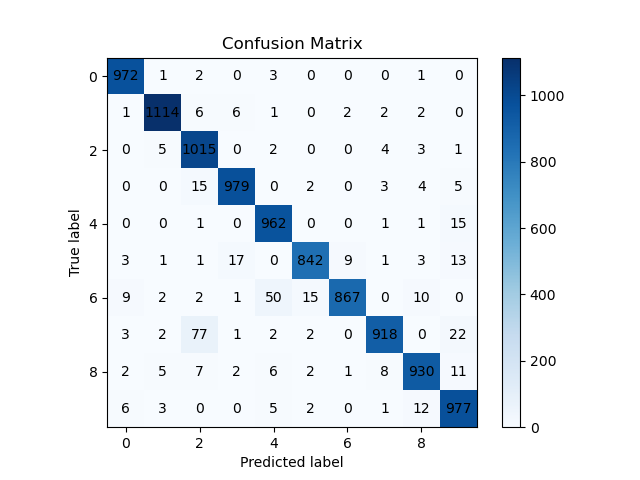
Confusion matrix with MNIST on training set
Classification results with multispectral images
The network was also tested with multispectral images. The training set contained a variable number of instances, depending on the specific multispectral image. Using the multispectral image of the Oitaven River, the network achieved an overall accuracy of 85.09%.
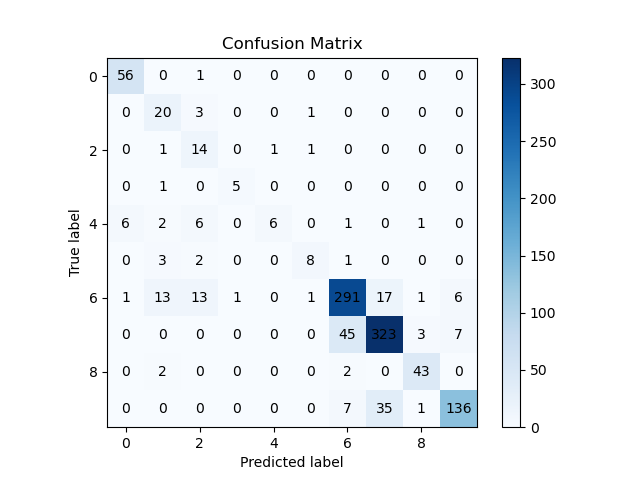
Confusion matrix with multispectral images on validation set
Quality of generated images
The network is capable of generating images similar to those in the training set. The simpler the images in the training set, the better the quality of the generated images. Therefore, the quality of the generated multispectral images is noticeably lower than that of the MNIST dataset images.
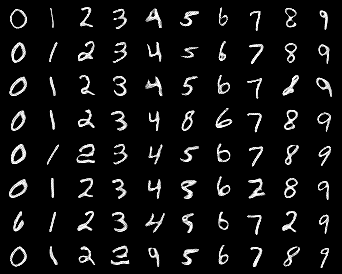
Generated MNIST images
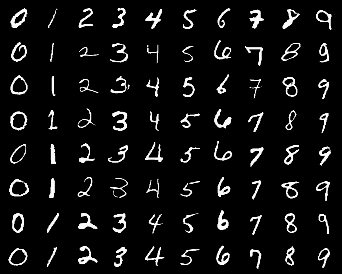
Real MNIST images

Generated Oitaven River multispectral images

Real Oitaven River multispectral images
Usage
Requirements
To begin, you need to clone the repository from GitHub. Use the following command:
git clone https://github.com/antongomez/Conditional-StyleGAN2.gitAfter cloning the repository, create a Conda environment with the required packages to run the network. The repository includes a file called environment.yml to streamline this process. Run the following command to set up the environment:
conda env create -f environment.ymlWe are currently updating the project's dependencies to support the latest package versions. If you'd like to contribute, check this issue.
Note: A GPU with CUDA support is required to run the network. All experiments were conducted on a TESLA T4 GPU with 16GB of memory.
Data
For this tutorial, you need to download the multispectral image of Pavia University from this OneDrive folder. This image is widely used in remote sensing and is in the public domain. In this case, we will use an adaptation that has only 5 channels, instead of 103 channels. Place the files in a folder named data/PAVIA and make sure the filenames are as follows:
- pavia_university.raw (Multispectral image)
- pavia_university_gt.pgm (Ground truth)
- pavia_university_seg.raw (Segmented image)
- pavia_university_seg_centers.raw (Centers of the segments)
The multispectral image of Pavia University contains 5 channels, but RGB channels can be extracted to visualize the image in color. There are 9 classes in the ground truth image, represented by the following colors:
- Asphalt: raspberry red
- Meadows: green
- Gravel: yellow
- Trees: blue
- Metal: orange
- Bare soil: purple
- Bitumen: light blue
- Bricks: light purple
- Shadows: light yellow
There are some pixels in the ground truth in black color that represent unknown classes. These pixels are not considered in the classification task.

Multispectral image of Pavia University in RGB
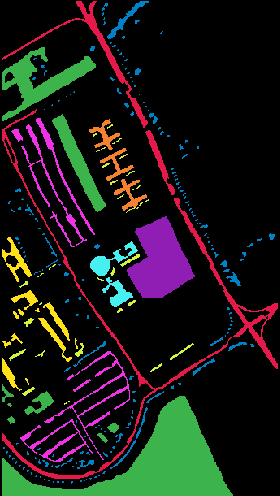
Ground truth of Pavia University image
Training
Once the environment is set up and the images are downloaded, you can train the network with the following command:
python cstylegan2/run.py data/PAVIA --channels=5 --num_train_steps=100 --evaluate_every=44 --save_every=44 --name=PAVIAFirst, the dataset will be loaded, consisting of a high-resolution multispectral image of Pavia University. The network uses 32x32 pixel patches from the multispectral image, centred on the segments defined in the pavia_university_seg_centers.raw file.
As the image has 5 channels, the --channels=5 flag specifies this. The dataset is split into training and validation sets, with the following default split:
- Training set: 15% of each class
- Validation set: 5% of each class
The batch size is set to 64 by default, creating 2837 patches for the training set and 960 for the validation set. A smaller training set is used to mimic situations with limited data, as seen in the original problem involving multispectral images from Galician river basins.
The network will train for 100 steps, saving a model every epoch (44 batches). If you modify the batch size and still want to save a model per epoch, adjust the number of steps for saving and evaluation by dividing the total number of batches by the batch size.
Evaluation
Image generation
During training, the network generates a mosaic of images every 44 batches (effectively after each epoch). This mosaic contains 8 generated images for each of the 9 classes in this classification problem. Initially, the generated images will be quite noisy, but as training progresses, the quality of the generated images will improve significantly.

Generated patches in epoch 10

Generated patches in epoch 100
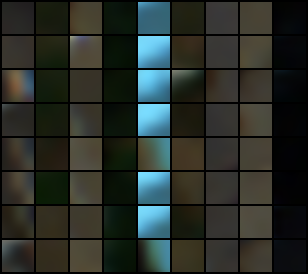
Real patches of Pavia University
After training is complete, you can generate images conditioned on specific class labels. The cstylegan2/test_G.py script in the GitHub repository allows you to generate images for each class in the dataset. This script accepts two parameters:
- name: The name used during training, in this case, PAVIA.
- model (optional): The number of the saved model to use. If not specified, the latest saved model will be used.
To run the script and generate images, use the following command:
python cstylegan2/test_G.py --name=PAVIAThe script will generate 8 images for each class in the dataset. These images will be saved in the test/PAVIA/G directory.
Classification
For the classification task, the network logs the overall accuracy and class-wise accuracy for both the training and validation sets each time a model is saved. To identify the best model from the training process, you can use the select_best_model.py script. This script analyses the validation log files and selects the model with the highest average accuracy.
python cstylegan2/select_best_model.py --name=PAVIAThe script returns the model number with the highest average accuracy. To evaluate this model, use the test_D.py script, which accepts the following parameters:
- folder: The directory where the dataset is stored, e.g., data/PAVIA.
- name: The name used for training the network, e.g., PAVIA.
- model: The number of the best model selected during training.
To evaluate the best saved model, run the following command:
python cstylegan2/test_D.py data/PAVIA --folder=data/PAVIA --name=PAVIA --model=NUMBER_OF_THE_BEST_MODELThe script will output the overall accuracy, average accuracy per class, and the accuracy for each individual class.
Applications
Remote Sensing and Environmental Monitoring
The network could be used for classifying multispectral remote sensing images, making it suitable for tasks such as land cover classification,environmental monitoring, anddisaster response. For example, it could assist in distinguishing between forests, urban areas, and water bodies, or evaluating the effects of natural disasters like floods or wildfires.
Precision Agriculture
The network could be used for crop health monitoring and weed detection in precision agriculture. It can help identify early signs of plant stress or disease, enabling farmers to optimize yields. Additionally, the network could automate the detection of weeds, supporting more efficient herbicide application and promoting sustainable farming.
Urban Planning and Development
The network could be applied to urban land use classification and infrastructure monitoring by analysing aerial or satellite images. This can assist urban planners in mapping urban expansion, monitoring roads and infrastructure development, and making decisions for sustainable city growth.
Data Augmentation and Synthetic Image Generation
The network could be used for data augmentation by generating synthetic images, particularly in cases of imbalanced datasets. This allows it to create additional data for minority classes, improving performance in tasks like training data generation and enhancing model accuracy when real-world data is limited.
Contributing
License
This project is licensed under GPL-v3 to ensure it remains fully open and collaborative. The GPL-v3 license allows anyone to freely use, modify, and distribute the code while guaranteeing that any derivative works also remain open-source. By adopting this license, the project fosters a community-driven environment that emphasizes transparency, innovation, and equal access, encouraging continuous contributions and ensuring that the spirit of open-source is preserved for future developments.